 Scan to join WeChat group
Scan to join WeChat groupREADME
🚀 Florentine.ai MCP 服务器 - 与你的 MongoDB 和 MySQL 数据对话
Florentine.ai 模型上下文协议(MCP)服务器允许你将针对 MongoDB 和 MySQL 数据的自然语言查询直接集成到自定义 AI 代理或 AI 桌面应用程序中。
AI 代理将问题转发给 MCP 服务器,服务器将其转换为数据库查询,然后将查询结果返回给代理进行进一步处理。
此外,它还具备一些额外功能,例如:
- 多租户使用的安全数据分离
- 自动模式探索
- 支持语义向量搜索/检索增强生成(RAG),可自动创建嵌入
- 高级查找支持
- 键排除
注意:如果你正在寻找我们的 API,可以点击此处。
🚀 快速开始
Florentine.ai MCP 服务器能让你轻松实现对 MongoDB 和 MySQL 数据的自然语言查询。以下是使用该服务器的基本步骤和相关信息。
✨ 主要特性
- 支持将自然语言查询集成到自定义 AI 代理或 AI 桌面应用中。
- 具备多租户使用的安全数据分离功能。
- 可自动进行模式探索。
- 支持语义向量搜索和 RAG,能自动创建嵌入。
- 提供高级查找支持和键排除功能。
📦 安装指南
MCP 服务器的详细文档可点击此处查看。
你可以使用 npx 轻松运行服务器。以下是针对 Claude 桌面应用(claude_desktop_config.json)的示例:
{
"mcpServers": {
"florentine": {
"command": "npx",
"args": ["-y", "@florentine-ai/mcp", "--mode", "static"],
"env": {
"FLORENTINE_TOKEN": "<FLORENTINE_API_KEY>"
}
}
}
}
💻 使用示例
基础用法
Florentine.ai MCP 服务器提供了两个实用工具,以下是它们的使用示例:
- florentine_list_collections:列出所有当前可查询的活动集合/表,包括描述、键和值的类型。
- florentine_ask:接收一个问题,并根据
returnTypes设置返回查询、查询结果或答案。
高级用法
在不同的集成模式下,你可以更灵活地使用 florentine_ask 工具,具体请参考后续的集成模式部分。
📚 详细文档
前提条件
- Node.js >= v18.0.0
- 一个 Florentine.ai 账户(可点击此处创建免费账户)
- 一个已连接的数据库,并且在你的 Florentine.ai 账户中至少有一个已分析并激活的集合/表
- 一个 Florentine.ai API 密钥(你可以在账户仪表盘中找到)
可用工具
- florentine_list_collections:列出所有当前可查询的活动集合/表,包括描述、键和值的类型。
- florentine_ask:接收一个问题,并根据
returnTypes设置返回查询、查询结果或答案。
参数说明
| 变量 | 是否必需 | 允许的值 | 描述 |
| ---- | ---- | ---- | ---- |
| --mode | 是 | static, dynamic | static(适用于现有的外部 MCP 客户端,如 Claude 桌面应用)或 dynamic(适用于自定义 MCP 客户端)。请参考集成模式部分。 |
| --debug | 否 | true | 启用将日志记录到外部文件。如果设置了该参数,则还需要设置 --logpath。 |
| --logpath | 否 | 绝对日志文件路径 | 调试日志的文件路径。如果设置了该参数,则还需要设置 --debug。 |
身份验证
Florentine.ai MCP 服务器使用 API 密钥对请求进行身份验证。你可以在账户仪表盘中查看和管理你的 API 密钥。该密钥必须作为环境变量添加到 MCP 服务器的配置设置中:
"env": {
"FLORENTINE_TOKEN": "<FLORENTINE_API_KEY>"
}
连接你的大语言模型(LLM)账户
Florentine.ai 采用自带密钥模式,因此你需要在 MCP 请求中提供你的 LLM API 密钥(OpenAI、Google、Anthropic、Deepseek)。
你有两种添加 LLM API 密钥的方式:
选项 1:将 LLM 密钥保存到你的账户中(推荐)
连接到 LLM 提供商的最简单方法是将你的 LLM API 密钥保存到Florentine.ai 仪表盘中。
- 添加你的 API 密钥
- 选择你的 LLM 提供商(OpenAI、Deepseek、Google 或 Anthropic)
- 点击保存
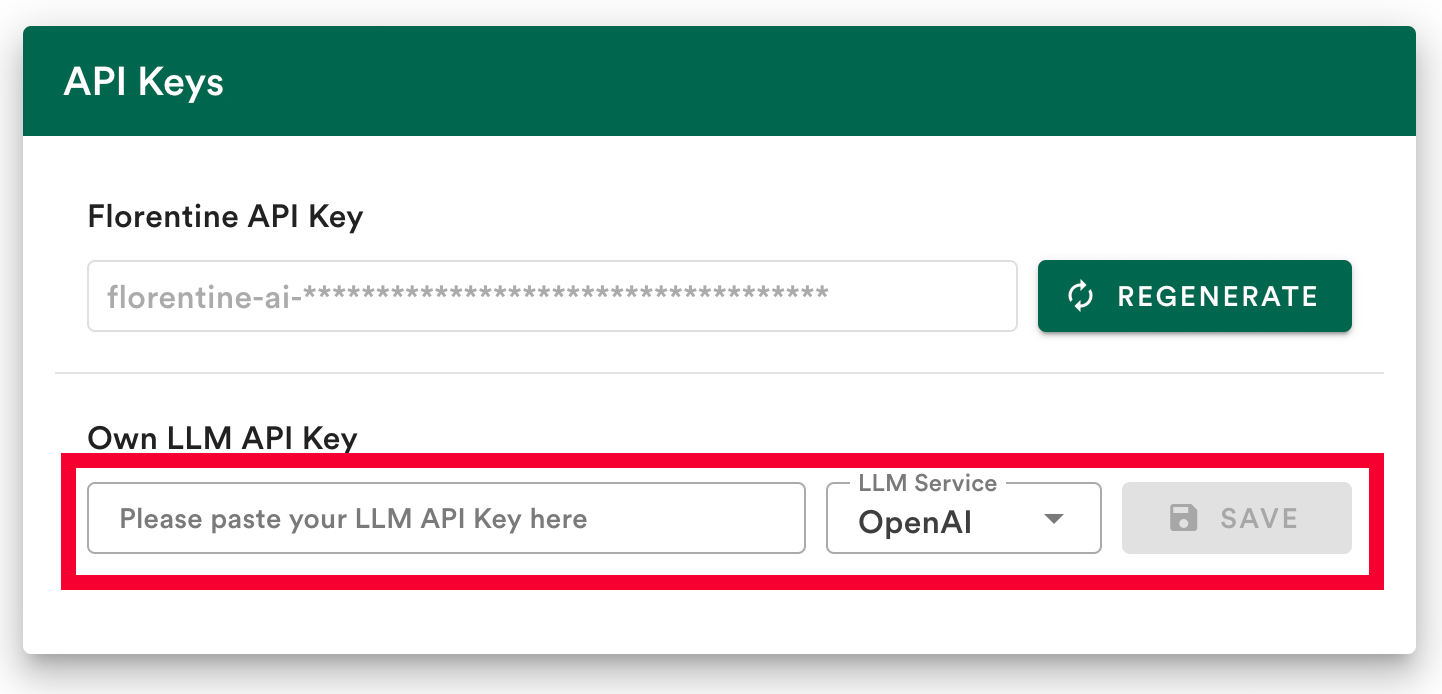
选项 2:在 MCP 服务器配置环境变量中提供 LLM 密钥
如果你不想将密钥存储在 Florentine.ai 账户中,或者想使用多个 LLM 密钥,可以在 MCP 服务器配置中传递密钥:
"env": {
"LLM_SERVICE": "<YOUR_LLM_SERVICE>",
"LLM_KEY": "<YOUR_LLM_API_KEY>"
}
| 参数 | 描述 | 允许的值 |
| ---- | ---- | ---- |
| LLM_SERVICE | 指定要使用的 LLM 提供商。 | openai、google、anthropic 或 deepseek |
| LLM_KEY | 你为所提供的 LLM 服务使用的 API 密钥。 | 有效的 API 密钥字符串 |
注意:如果你在 MCP 服务器配置的环境变量中提供了
LLM_KEY,它将覆盖你账户中存储的任何密钥。
集成模式
你需要在 MCP 服务器配置的 args 数组中设置操作模式为 static 或 dynamic:
"args": [
"-y",
"@florentine-ai/mcp",
"--mode",
"static"
]
静态模式
如果你要将 Florentine.ai 集成到现有的外部 MCP 客户端(如 Claude 桌面应用或 Dive AI 等支持 MCP 的桌面应用),则应使用静态模式。
在 static 模式下,你将所有参数(如返回类型、必需输入等)作为环境变量设置在配置 JSON 中。这意味着这些参数将保持静态,直到你更改设置配置,并且每次向 Florentine.ai 发送请求时都会包含这些参数。以下是一个示例:
{
"mcpServers": {
"florentine": {
"command": "npx",
"args": ["-y", "@florentine-ai/mcp", "--mode", "static"],
"env": {
"FLORENTINE_TOKEN": "<FLORENTINE_API_KEY>",
"SESSION_ID": "6f7d62f9-8ceb-456b-b7ef-6bd869c3b13a",
"LLM_SERVICE": "openai",
"LLM_KEY": "<YOUR_OPENAI_KEY>",
"RETURN_TYPES": "[\"result\"]",
"REQUIRED_INPUTS": "[{\"keyPath\":\"accountId\",\"value\":\"507f1f77bcf86cd799439011\"}]"
}
}
}
}
环境变量
| 变量 | 是否必需 | 类型 | 描述 |
| ---- | ---- | ---- | ---- |
| FLORENTINE_TOKEN | 是 | 字符串 | 你的 Florentine.ai API 密钥,可从仪表盘复制。 |
| SESSION_ID | 否 | 字符串 | 客户端的会话 ID,用于服务器端聊天历史记录。请参考会话部分。 |
| LLM_SERVICE | 否 | 字符串 | 指定要使用的 LLM 提供商。仅当你未将 LLM 密钥保存到 Florentine.ai 账户中时才需要。请参考连接你的 LLM 账户部分。 |
| LLM_KEY | 否 | 字符串 | 你为所提供的 LLM 服务使用的 API 密钥。仅当你未将 LLM 密钥保存到 Florentine.ai 账户中时才需要。请参考连接你的 LLM 账户部分。 |
| RETURN_TYPES | 否 | 字符串化的 JSON | florentine_ask 工具调用的返回类型。请参考返回类型部分。 |
| REQUIRED_INPUTS | 否 | 字符串化的 JSON | 必需输入。请参考多租户使用的安全数据分离部分。 |
动态模式
如果你要将 Florentine.ai 集成到自己的自定义 MCP 客户端中,则应使用动态模式。
在动态模式下,你可以将所有参数(如返回类型、必需输入等)直接传递给 florentine_ask 工具。这意味着你可以为转发给 Florentine.ai 的每个请求动态注入单个参数(例如用户 ID)。
为了能够动态传递值,你需要在自定义客户端/代理中覆盖 florentine_ask 工具方法。以下是一个使用标准 @modelcontextprotocol TypeScript SDK 的示例:
import { StdioClientTransport } from '@modelcontextprotocol/sdk/client/stdio.js';
import { Client } from '@modelcontextprotocol/sdk/client/index.js';
import { fetchUserSpecificData } from './userService.js';
// 创建 MCP 客户端实例
const mcpClient = new Client({
name: 'florentine',
version: '1.0.0'
});
// 定义 MCP 设置配置
const mcpSetupConfig = new StdioClientTransport({
command: 'npx',
args: ['-y', '@florentine-ai/mcp', '--mode', 'dynamic'],
env: {
FLORENTINE_TOKEN: '<FLORENTINE_API_KEY>'
}
});
// 连接 MCP 客户端
await mcpClient.connect(mcpSetupConfig);
// 将原始 callTool 函数保存到变量中
const originalCallTool = mcpClient.callTool;
// 动态获取并添加 florentine_ask 参数(模拟实现)
const enhanceAskParameters = async ({ question }: { question: string }) => {
return {
question,
// 模拟用户数据获取(例如 returnTypes、requiredInputs 等),
// 请替换为实际实现
...(await fetchUserSpecificData({ userId: '<USER_ID>' }))
};
};
// 用自定义实现覆盖 callTool 函数
// 使用动态注入的参数增强 florentine_ask 方法
mcpClient.callTool = async (params, resultSchema, options) => {
if (params.name === 'florentine_ask')
params.arguments = await enhanceAskParameters(
params.arguments as unknown as { question: string }
);
return await originalCallTool(params, resultSchema, options);
};
// 调用 florentine_ask 工具将自动增强参数
const result = await mcpClient.callTool({
name: 'florentine_ask',
arguments: {
question: 'Who won the last tabletennis match?'
}
});
示例详解
让我们详细看看上述示例中发生了什么。
首先,我们创建并连接 MCP 客户端:
const mcpClient = new Client({
name: 'florentine',
version: '1.0.0'
});
const mcpSetupConfig = new StdioClientTransport({
command: 'npx',
args: ['-y', '@florentine-ai/mcp', '--mode', 'dynamic'],
env: {
FLORENTINE_TOKEN: '<FLORENTINE_API_KEY>'
}
});
await mcpClient.connect(mcpSetupConfig);
注意:你也可以在
dynamic模式下使用环境变量。但是,如果你动态指定参数,这些参数将覆盖现有环境变量中的参数值。
接下来,我们将原始的 callTool 函数保存到一个变量中:
const originalCallTool = mcpClient.callTool;
然后,我们创建一个 enhanceAskParameters 函数,该函数接受一个问题作为输入,为用户获取额外的参数(例如 returnTypes、requiredInputs 等),并返回合并后的参数:
const enhanceAskParameters = async ({ question }: { question: string }) => {
return {
question,
// 示例函数,用于获取额外数据,例如用户特定的 requiredInputs
...(await fetchUserSpecificData({ userId: '<USER_ID>' }))
};
};
然后,我们用一个实现覆盖原始的 callTool 函数,该实现使用来自 enhanceAskParameters 的参数增强 florentine_ask 工具,并调用我们保存到变量 originalCallTool 中的原始 callTool 函数:
mcpClient.callTool = async (params, resultSchema, options) => {
if (params.name === 'florentine_ask')
params.arguments = await enhanceAskParameters(
params.arguments as unknown as { question: string }
);
return await originalCallTool(params, resultSchema, options);
};
最后,我们可以使用一个问题调用 florentine_ask 工具,并动态注入用户特定的参数:
const result = await mcpClient.callTool({
name: 'florentine_ask',
arguments: {
question: 'Who won the last tabletennis match?'
}
});
重要提示: 请确保在不覆盖
florentine_ask实现的情况下永远不要使用动态模式。 如果你不覆盖它,你的客户端/代理将直接使用florentine_ask工具的 MCP 服务器端实现以及所有额外参数。 因此,客户端/代理将自行决定为returnTypes、requiredInputs等填充哪些值。 这将导致意外行为,并导致错误和错误结果。
florentine_ask 参数
| 变量 | 是否必需 | 类型 | 描述 |
| ---- | ---- | ---- | ---- |
| sessionId | 否 | 字符串 | 客户端的会话 ID,用于服务器端聊天历史记录。请参考会话部分。 |
| returnTypes | 否 | Array<String> | florentine_ask 工具调用的返回类型。请参考返回类型部分。 |
| requiredInputs | 否 | Array<Object> | 必需输入。请参考多租户使用的安全数据分离部分。 |
返回类型
默认情况下,florentine_ask 工具返回你在 Florentine.ai 账户中配置的结果类型(默认:result)。你可以通过指定一个 returnTypes 数组,在每个请求中覆盖此设置,该数组可以包含以下三个步骤的任意组合:
- 查询生成:将问题转换为数据库查询(MongoDB 聚合管道或 MySQL 查询)。
- 查询执行:使用你提供的连接字符串对数据库执行查询。
- 答案生成:将结构化结果转换为自然语言答案。
提供返回类型
你有两种方式包含 returnTypes 数组:
- 作为 MCP 设置配置中的
RETURN_TYPES环境变量(在static和dynamic模式下均可用) - 作为
florentine_ask工具的returnTypes参数(仅在dynamic模式下可用)
作为环境变量,你需要将值作为字符串化的 JSON 数组提供:
"env": {
"RETURN_TYPES": "[\"query\",\"result\",\"answer\"]"
}
作为工具参数,你需要将值作为数组提供:
{
"returnTypes": ["query", "result", "answer"]
}
返回类型配置
你可以通过指定一个 returnTypes 数组,选择返回哪些步骤的结果,该数组可以包含以下任意组合:
| returnTypes 值 | 描述 | 响应中预期的键 |
| ---- | ---- | ---- |
| "query" | 返回生成的数据库查询、使用的数据库和集合/表、0 到 10 的置信度得分以及数据库类型("mongodb" 或 "mysql")。 | confidence, database, collection, query, databaseType |
| "result" | 返回执行查询后的原始查询结果。 | result |
| "answer" | 根据执行查询的结果返回自然语言响应。 | answer |
多租户使用的安全数据分离
你可以通过确保查询根据提供的值过滤数据来启用安全数据分离,我们将这些值称为 必需输入。
这些值由 Florentine.ai 转换层在大语言模型生成查询后添加到查询中。因此,Florentine.ai 可以确保每个用户只能检索到他有权限访问的数据。
键在你的账户中被定义为 必需输入,请参考我们官方文档中的相关部分了解如何操作。
提供必需输入
你有两种方式包含 requiredInputs 数组:
- 作为 MCP 设置配置中的
REQUIRED_INPUTS环境变量(在static和dynamic模式下均可用) - 作为
florentine_ask工具的requiredInputs参数(仅在dynamic模式下可用)
作为环境变量,你需要将值作为字符串化的 JSON 数组提供:
"env": {
"REQUIRED_INPUTS": "[{\"keyPath\":\"userId\",\"value\":\"507f1f77bcf86cd799439011\"}]"
}
作为工具参数,你需要将值作为数组提供:
"requiredInputs": [
{
"keyPath": "userId",
"value": "507f1f77bcf86cd799439011"
}
]
如果你在多个集合/表中有相同 keyPath 但不同 value 的必需输入,你还可以提供 database 和 collections 数组:
{
"requiredInputs": [
{
"keyPath": "name",
"value": "Sesame Street",
"database": "rentals",
"collections": ["houses"]
},
{
"keyPath": "name",
"value": { "$in": ["Ernie", "Bert"] },
"database": "rentals",
"collections": ["tenants"]
}
]
}
必需输入配置
| 字段 | 是否必需 | 类型 | 描述 | 约束 |
| ---- | ---- | ---- | ---- | ---- |
| keyPath | 是 | 字符串 | 要过滤的字段的路径。 | 必须是有效的键路径。 |
| value | 是 | 任意 | 用于过滤的值(特定类型,请参考支持的值类型)。 | 必须与字段的类型匹配(字符串、ObjectId、布尔值、数字或日期)。 |
| database | 否 | 字符串 | 包含要过滤的集合的数据库。 | 如果提供了 collections,则必须提供该字段。 |
| collections | 否 | Array<String> | 要应用过滤的数据库中的特定集合/表。 | 必须包含至少一个集合/表。 |
支持的值类型
根据键的值类型,你可以提供不同的 必需输入 值:
| 类型 | 格式示例 | 支持的运算符 | 注意事项 |
| ---- | ---- | ---- | ---- |
| 字符串 或 字符串数组 | "text"
{ $in: ["text1", "text2"] } | $in | 区分大小写。 |
| ObjectId 或 ObjectId 数组 | "507f191e810c19729de860ea"
{ $in: ["507f191e810c19729de860ea", "507f191e810c19729de860eb"] } | $in | 以字符串形式提供。 |
| 布尔值 | true/false | — | 仅支持精确值。 |
| 数字 或 数字数组 | 42
{ $gt: 10, $lte: 100 }
{ $in: [1, 2, 3] }
{ $in: [{$gte:1}, {$lt:10}] } | $gt, $gte, $lt, $lte, $in | 支持小数。 |
| 日期 或 日期数组 | "2024-01-01T00:00:00Z"(UTC)
"2024-01-01T00:00:00-05:00"(时区偏移) | $gt, $gte, $lt, $lte, $in | ISO 8601 格式。 |
使用示例
注意:我们仅提供作为工具参数输入的示例。对于环境变量实现,你只需将键名更改为
REQUIRED_INPUTS并将 JSON 字符串化。
示例类型:字符串
用例:用户只能查看他经常与之对战的球员的统计数据。
解决方案:通过球员姓名将访问权限限制为一组 4 名球员。
const res = await FlorentineAI.ask({
question: 'Which player had the most wins?',
requiredInputs: [
{
keyPath: 'name',
value: { $in: ['Megan', 'Frank', 'Jen', 'Bob'] }
}
]
});
示例类型:ObjectId
用例:用户只能查看他自己产品的收入情况。
解决方案:通过账户 ID 将访问权限限制为一个特定账户。
const res = await FlorentineAI.ask({
question: 'Whats the revenue of my products?',
requiredInputs: [
{
keyPath: 'accountId',
value: '507f1f77bcf86cd799439011'
}
]
});
示例类型:布尔值
用例:对客户的所有分析应仅针对付费客户进行。
解决方案:通过 isPaidAccount 将访问权限限制为仅付费客户。
const res = await FlorentineAI.ask({
question: 'How many customers registered in the last year?',
requiredInputs: [
{
keyPath: 'isPaidAccount',
value: true
}
]
});
示例类型:数字
用例:员工只能查看低于一定金额的付款信息。
解决方案:通过金额将访问权限限制为低于 10000 的付款。
const res = await FlorentineAI.ask({
question: 'List all payments we received.',
requiredInputs: [
{
keyPath: 'amount',
value: { $lt: 10000 }
}
]
});
示例类型:日期
用例:财务数据分析应仅包括特定的一年的数据。
解决方案:通过 transactionDate 将访问权限限制为 2024 年的所有交易。
const res = await FlorentineAI.ask({
question: 'What was our revenue, profit and margin per month?',
requiredInputs: [
{
keyPath: 'transactionDate',
value: {
$gte: '2023-01-01T00:00:00Z',
$lt: '2024-01-01T00:00:00Z'
}
}
]
});
会话
会话允许 Florentine.ai 启用服务器端聊天历史记录。
由于包含 MCP 服务器的客户端/代理通常会自行跟踪聊天历史记录,因此添加会话并非绝对必要。
然而,这可能仍然有助于 Florentine.ai 更好地理解上下文,并可能提高结果质量。
提供会话
你有两种方式包含 sessionId:
- 作为 MCP 设置配置中的
SESSION_ID环境变量(在static和dynamic模式下均可用) - 作为
florentine_ask工具的sessionId参数(仅在dynamic模式下可用)
作为环境变量:
"env": {
"SESSION_ID": "<YOUR_SESSION_ID>"
}
作为工具参数:
{
"sessionId": "<YOUR_SESSION_ID>"
}
错误处理
MCP 服务器工具调用的所有错误都遵循以下一致的 JSON 结构:
{
"error": {
"name": "FlorentineApiError",
"statusCode": 500,
"message": "The provided Florentine API key is invalid. You can find the key in your account settings: https://florentine.ai/settings",
"errorCode": "INVALID_TOKEN",
"requestId": "abc123"
}
}
| 字段 | 类型 | 描述 |
| ---- | ---- | ---- |
| name | 字符串 | 错误类名(例如 FlorentineApiError、FlorentineConnectionError) |
| statusCode | 数字 | HTTP 状态码(例如 400、500) |
| message | 字符串 | 对出错原因的解释 |
| errorCode | 字符串 | 错误标识符(例如 NO_TOKEN、INVALID_LLM_KEY) |
| requestId | 字符串 | 此请求的唯一 ID(有助于支持和调试) |
自定义客户端错误处理
错误对象以字符串化的 JSON 形式返回到 content 数组中:
{
"content": [
{
"type": "text",
"text": "{\"error\":{\"name\":\"FlorentineApiError\",\"statusCode\":401,\"message\":\"The provided Florentine API key is invalid. You can find the key in your account settings: https://florentine.ai/settings\",\"errorCode\":\"INVALID_TOKEN\",\"requestId\":\"uhv99g\"}}"
}
],
"isError": true
}
你可以解析 text 中的 JSON,并在自定义客户端/代理中处理不同的错误。
常见错误
| 错误名称 | 错误代码 | 含义 |
| ---- | ---- | ---- |
| FlorentineApiError | MODE_MISSING | 你必须提供 static 或 dynamic 作为模式参数 |
| FlorentineApiError | MODE_INVALID | 模式无效(必须是 static 或 dynamic) |
| FlorentineApiError | INVALID_TOKEN | Florentine API 密钥无效 |
| FlorentineApiError | LLM_KEY_WITHOUT_SERVICE | 如果定义了 llmKey,则必须提供 llmService |
| FlorentineApiError | LLM_SERVICE_WITHOUT_KEY | 如果定义了 llmService,则必须提供 llmKey |
| FlorentineApiError | INVALID_LLM_SERVICE | 提供的 llmService 无效 |
| FlorentineApiError | NO_OWN_LLM_KEY | 你需要提供自己的 LLM 密钥 |
| FlorentineApiError | NO_ACTIVE_COLLECTIONS | 账户中没有激活的集合/表 |
| FlorentineApiError | MISSING_REQUIRED_INPUT | 缺少必需输入 |
| FlorentineApiError | INVALID_REQUIRED_INPUT | 必需输入无效 |
| FlorentineApiError | INVALID_REQUIRED_INPUT_FORMAT | 必需输入格式无效 |
| FlorentineApiError | NO_QUESTION | 缺少问题 |
| FlorentineApiError | EXECUTION_FAILURE | 创建的查询执行失败 |
| FlorentineApiError | NO_CHAT_ID | 需要历史聊天 ID 但缺少 |
| FlorentineApiError | TOO_MANY_TOKENS | 查询提示超过了 LLM 模型的最大令牌数 |
| FlorentineLLMError | API_KEY_ISSUE | LLM API 密钥无效 |
| FlorentineLLMError | NO_RETURN | Florentine.ai 未收到有效的 LLM 返回 |
| FlorentineLLMError | RATE_LIMIT_EXCEEDED | LLM 请求大小过大 |
| FlorentineConnectionError | CONNECTION_REFUSED | 无法连接到数据库以执行查询 |
| FlorentineCollectionError | NO_EXECUTION | 创建的查询无法执行 |
| FlorentinePipelineError | MODIFICATION_FAILED | 修改查询管道失败 |
| FlorentineUsageError | LIMIT_REACHED | 你计划中包含的所有 API 请求已耗尽 |
| FlorentineUnknownError | UNKNOWN_ERROR | 所有发生的未知错误 |