 扫码联系在线客服
扫码联系在线客服🎬 视频字幕合成技能 V3.6
固定程序模式 — AI 对话式引导,自动配置,一键执行。无需用户手动操作。
🔔 首次加载指引
加载本技能后,必须立即向用户推送以下信息:
🎬 视频字幕合成 V3.6 已就绪!
只需告诉我:
• 源视频文件路径
• 字幕模板文件路径(.md 格式)
其他一切交给我——环境检测、引擎配置、TTS配音、字幕注入,全自动完成。
💡 制作字幕模板?推荐使用「字幕模板编辑器」:
用浏览器打开 tools/subtitle-editor.html → 拖入视频 → 粘贴字幕文案 → 按 F 键拍板标记 → 导出 .md
📂 技能文件
<本技能目录>/
├── SKILL.md
├── scripts/ ← AI 从这里复制程序到用户项目
│ ├── env_check.py
│ ├── step01_check.py
│ ├── step02_cut.py
│ ├── step03_tts.py
│ ├── step04_align.py
│ ├── step05_merge.py
│ ├── step06_finalize.py
│ ├── pipeline.py
│ ├── copy_template.py
│ └── script_template.md
├── tools/ ← 辅助工具
│ └── subtitle-editor.html ← 字幕模板编辑器(按键拍板式)
└── references/
└── DESIGN.md
🤖 AI 对话交互流程(核心)
阶段 1:接收用户请求
用户说"帮我合成视频"或类似请求。AI 必须确认两个路径:
请提供:
1. 源视频路径(如 D:/视频/demo.mp4 或 /home/user/video/demo.mp4)
2. 配音模板路径(如 D:/视频/script.md 或 /home/user/video/script.md)
如果用户没有模板:AI 必须执行以下操作:
python <本技能目录>/scripts/copy_template.py --to-dir <用户项目目录>执行后告知用户:"📝 模板已复制到
<用户项目目录>/script_template.md,请打开填写时间点和文案,完成后告诉我路径即可合成。"
阶段 1.5:AI 展示模板格式(用户有模板时也执行)
当用户提供了模板路径,但 AI 需要在对话中展示格式参考时:
python <本技能目录>/scripts/copy_template.py --chat
读取 stdout 输出,向用户展示模板格式说明。
阶段 2:环境检测(AI 自动执行)
AI 自行执行,无需用户干预:
-
复制程序:将本技能
scripts/目录下的所有.py文件复制到用户当前项目目录。- AI 已知本技能的安装路径(加载时系统会告知)
- 用文件操作工具复制,不要写死绝对路径
- Windows/Linux 均使用各自系统的文件 API
-
运行环境检测:
python env_check.py --output env.json
读 env.json,按情况处理:
| env.json 状态 | AI 行为 |
|-------------|---------|
| missing 含 ffmpeg | 告知用户:"📦 需要安装 ffmpeg。下载地址:https://www.gyan.dev/ffmpeg/builds/ → 下载 essentials_build → 解压到任意目录 → 告诉我路径" |
| missing 含 websocket-client | AI 自行执行:pip install websocket-client==1.8.0,失败则加国内镜像 -i https://pypi.tuna.tsinghua.edu.cn/simple |
| 全部通过 | 进入阶段 3 |
阶段 3:TTS 引擎选择(AI 提问 + 用户选择)
AI 必须主动提问,原文如下:
🔊 请选择 TTS 配音引擎:
1. 讯飞超拟人(推荐)— 音质最佳,需讯飞账号凭证
2. edge-tts(免费备用)— 微软服务,无需配置
请输入 1 或 2:
用户选 1(讯飞):
AI 追问凭证:
请提供讯飞凭证(在 https://console.xfyun.cn 获取):
• APPID:
• APIKey:
• APISecret:
• WS URL(如不确定,使用默认值 wss://cbm01.cn-huabei-1.xf-yun.com/v1/private/mcd9m97e6)
(凭证仅保存在本地的 tts_config.json,不会上传)
安全提醒:凭证写入
tts_config.json后,提醒用户将此文件加入.gitignore。
用户提供凭证后,AI 问音色:
🎤 请选择讯飞音色:
1. 聆小糖(女,活泼流畅)— 默认,适合通用教学
2. 聆小璇(女,柔美自然)
3. 聆飞逸(男,稳重有力)
4. 聆小玥(女,清晰明亮)
5. 聆玉昭(女,自然亲切)
请输入 1-5(默认 1):
根据用户选择,映射为 vcn:
- 1 →
x5_lingxiaotang_flow - 2 →
x5_lingxiaoxuan_flow - 3 →
x5_lingfeiyi_flow - 4 →
x5_lingxiaoyue_flow - 5 →
x5_lingyuzhao_flow
AI 创建 tts_config.json:
{
"spark": {
"app_id": "<用户提供>",
"api_key": "<用户提供>",
"api_secret": "<用户提供>",
"ws_url": "<用户提供>",
"default_voice": "<用户选择的vcn>"
}
}
用户选 2(edge-tts):
AI 问音色:
🎤 请选择 edge-tts 音色:
1. 晓晓(女,温柔)— 默认
2. 云希(男,正式)
3. 晓伊(女,活泼)
请输入 1-3(默认 1):
根据选择映射:
- 1 →
zh-CN-XiaoxiaoNeural - 2 →
zh-CN-YunxiNeural - 3 →
zh-CN-XiaoyiNeural
不需要 tts_config.json,跳过创建。
用户说"没有讯飞 key":
AI 直接走 edge-tts 流程,不追问。
阶段 4:AI 自动生成 job.yaml
AI 根据已收集的信息,自动创建 job.yaml:
video: "<用户在阶段1给出的视频路径>"
template: "<用户在阶段1给出的模板路径>"
voice: "<阶段3选择的音色>"
engine: "<spark 或 edge>"
output_root: "output"
env_file: "env.json"
tts_config: "tts_config.json"
# template_fps: 30 # 高级:手动指定模板帧率(程序默认自动检测,通常无需设置)
如果 engine=edge,不写
tts_config这一行,或写tts_config: ""。
阶段 5:AI 一键执行(不是让用户执行)
AI 自行执行以下命令,并在对话中报告进度:
python pipeline.py --job job.yaml
将 pipeline.py 的标准输出实时展示给用户。每完成一步报告一次:
✅ 01_check → 10段解析完成
✅ 02_cut → 10段切分完成
✅ 03_tts → 10段配音完成(讯飞spark)
✅ 04_align → 3段填充 + 7段冻结扩展
✅ 05_merge → 10段声画合成完成
✅ 06_finalize → 字幕注入完成
🎉 成品:output/{task_id}/06_final/final_with_subs_xxx.mp4
阶段 6:容错处理
如果某步骤失败,pipeline.py 会输出 resume 命令。AI 必须:
- 读错误信息,判断原因
- 常见情况:
| 错误 | 处理 | |------|------| | 讯飞某段 TTS 超时 | 直接执行 resume 命令重试 | | ffmpeg 命令失败 | 检查路径/权限,告知用户 | | 模板解析失败 | 分析 report.json,提示用户修改模板 |
- 执行 resume:
python pipeline.py --job job.yaml --resume-from <失败的步骤>
📋 配置清单(AI 记住)
| 文件 | 谁创建 | 何时创建 | 内容 |
|------|--------|----------|------|
| env.json | AI 自动 | 阶段 2 | 环境检测结果 |
| tts_config.json | AI 自动 | 阶段 3(仅 spark) | 讯飞凭证 |
| job.yaml | AI 自动 | 阶段 4 | 任务配置 |
| output/ | pipeline 自动 | 阶段 5 | 所有输出 |
用户不需要手动创建或编辑任何文件。一切由 AI 对话引导完成。
🎤 音色速查(供 AI 参考)
讯飞 spark
| # | 名称 | vcn | 风格 |
|---|------|-----|------|
| 1 | 聆小糖 | x5_lingxiaotang_flow | 女,活泼流畅(默认) |
| 2 | 聆小璇 | x5_lingxiaoxuan_flow | 女,柔美自然 |
| 3 | 聆飞逸 | x5_lingfeiyi_flow | 男,稳重有力 |
| 4 | 聆小玥 | x5_lingxiaoyue_flow | 女,清晰明亮 |
| 5 | 聆玉昭 | x5_lingyuzhao_flow | 女,自然亲切 |
edge-tts
| # | 名称 | voice | 风格 |
|---|------|-------|------|
| 1 | 晓晓 | zh-CN-XiaoxiaoNeural | 女,温柔(默认) |
| 2 | 云希 | zh-CN-YunxiNeural | 男,正式 |
| 3 | 晓伊 | zh-CN-XiaoyiNeural | 女,活泼 |
⚠️ 环境缺失处理指南
| 缺失项 | AI 必须告知用户 |
|--------|---------------|
| ffmpeg | "请安装 ffmpeg。Windows: https://www.gyan.dev/ffmpeg/builds/ → 下载 essentials_build → 解压 → 把 bin/ 路径告诉我。Linux: sudo apt install ffmpeg 或 brew install ffmpeg" |
| Python | "需要 Python 3.7+:https://www.python.org/downloads/" |
| websocket-client | AI 自动执行:pip install websocket-client==1.8.0。如失败,尝试国内镜像:pip install websocket-client==1.8.0 -i https://pypi.tuna.tsinghua.edu.cn/simple |
| edge-tts(选了 edge 引擎时) | AI 自动执行:pip install edge-tts==7.2.8。如失败,尝试国内镜像:pip install edge-tts==7.2.8 -i https://pypi.tuna.tsinghua.edu.cn/simple。注意:这是 Python 包,不是微软商店的 EdgeTTS 应用。 |
重要:
edge-tts==7.2.8是 Python 包(pip install edge-tts==7.2.8),利用微软 Edge 浏览器的免费 TTS 服务。不是微软商店的 EdgeTTS 应用。不需要用户去微软商店下载。国内网络如 pip 直连失败,AI 自动追加-i https://pypi.tuna.tsinghua.edu.cn/simple重试。
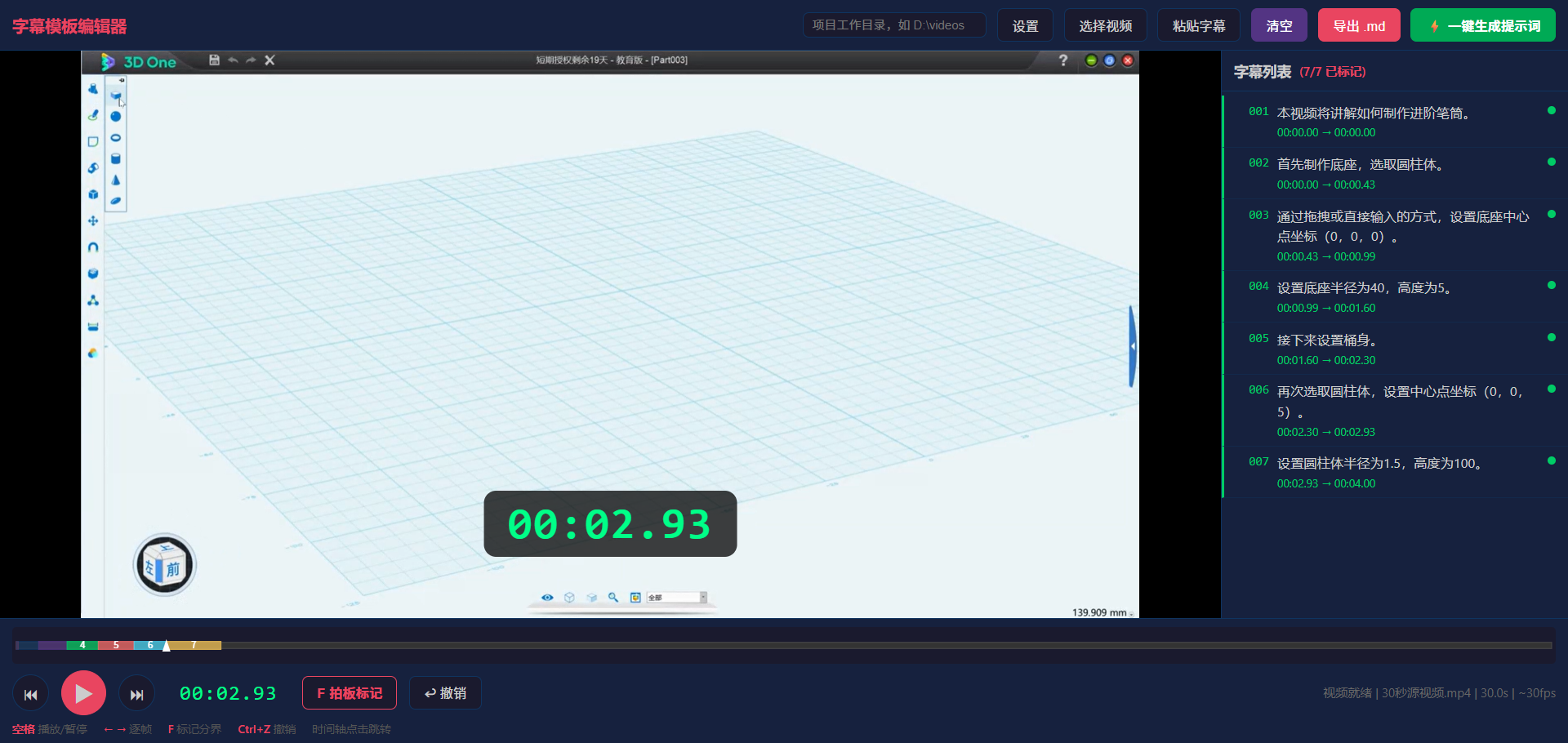
🖱️ 字幕模板编辑器("按键拍板" — 推荐制模方式)V3.5.6
目的:解决老师对照视频手动写时间码的痛点。
工具路径:<本技能目录>/tools/subtitle-editor.html
工作流
准备字幕文案 → 设工作目录 → 拖入视频 → 粘贴文案 → 播放视频 → 按F键拍板 → ⚡一键生成提示词
| 步骤 | 操作 | 说明 |
|------|------|------|
| 1 | 编写文案 | 用记事本写好字幕,按 001/002/003 编号 |
| 2 | 打开工具 | 双击 subtitle-editor.html,浏览器打开 |
| 3 | 设工作目录 | 工具栏输入项目绝对路径(如 D:\项目\视频),点击设置 |
| 4 | 拖入视频 | 把视频文件拖到浏览器窗口 |
| 5 | 粘贴字幕 | 点击「粘贴字幕」,把序号文案粘贴进去 |
| 6 | 按键拍板 | 播放视频,每到一个切换点按 F 键;← → 精调(单击1帧,按住8x快进) |
| 7 | 一键生成 | 点击 ⚡ 一键生成提示词 → 自动下载.md + 复制提示词到剪贴板 |
核心机制
- F 键 = 拍板标记:每次按下,当前视频时间自动对应到当前字幕的结束时间
- 自动衔接:上一段结束时间 = 下一段开始时间(无缝连续)
- 精确逐帧:单击 ← → 精确走 1 帧;长按 → 8x 高速播放(playbackRate,丝滑不卡)
- Ctrl+Z 撤销:按错了随时撤销上一个标记
- 自动缓存:所有标记 + 工作目录自动保存到 localStorage,关闭浏览器也不丢
- 一键生成提示词:⚡ 自动下载 .md + 构建完整提示词 + 复制到剪贴板,直接粘贴给 AI
- 路径校验:工作目录 3 层校验(无效字符/非绝对路径/像文件名),防止误存
AI 引导话术
当用户不知道如何制作模板时,AI 应主动推荐:
建议使用「字幕模板编辑器」制作模板,比手动写快很多:
1. 先用记事本写好每段字幕文案(按顺序编号)
2. 用浏览器打开 tools/subtitle-editor.html
3. 设置工作目录 → 拖入视频 → 粘贴字幕 → 播放视频
4. 每到画面切换点,按 F 键标记;← → 精调位置
5. 全部标记完成 → 点击 ⚡ 一键生成提示词
6. 把生成的提示词粘贴给我即可
📝 模板格式(供用户参考)
| 开始时间 | 结束时间 | 文案内容 |
|----------|----------|----------|
| 00:00 | 00:02 | 本视频将讲解如何制作进阶笔筒。 |
| 00:02 | 00:03,17 | 首先制作底座,选取圆柱体。 |
- 时间
MM:SS,帧数后缀MM:SS,FF - SMPTE 时间码:逗号后为帧编号(如
00:12,19= 12 + 19/fps 秒),非小数点 - 自动适配:程序检测到
MM:SS,FF逗号格式时,自动按 30fps(剪映默认帧率)解析,用户无需任何配置 - 也支持小数点格式
MM:SS.mmm - 数学符号自动口语化:
-5→ 朗读"负5"、5+3→ "5加3"、×→ "乘"、÷→ "除以"(无需手动改写) - 文件编码 UTF-8 / GBK 均支持
📋 变更日志
| 版本 | 日期 | 变更 |
|------|------|------|
| 3.6 | 2026-05-15 | 多音字标注功能:step03_tts.py 新增 normalize_polyphone() 和 pinyin_to_sapi() 函数——用户可在模板中用 {拼音+声调} 标记多音字正确读音(如 倒{dao3}角),标注不出现在字幕中;edge-tts 通过 SSML <phoneme alphabet='sapi'> 精确控制发音;讯飞 spark 去除标注依赖模型上下文。script_template.md 新增多音字标注文档。 |
363→| 3.5 | 2026-05-14 | TTS韵律优化 + 字幕编辑器 V3.5.6:step03_tts.py 新增 normalize_prosody() 自动韵律预处理——用户可在模板中用 | 标记强制断句(不出现在字幕中),第X步 后自动插入逗号换气;script_template.md 新增 | 标记文档。字幕编辑器方向键双模式重构、路径校验、一键提示词。 |
| 3.3 | 2026-05-13 | 模板文档完善:script_template.md 重写,新增三种时间格式对照表(MM:SS / MM:SS,FF / MM:SS.mmm),重点标注逗号=帧分隔符非小数点,增加帧号示例和剪映查看指引。 |
| 3.2 | 2026-05-13 | 修复视频切分帧偏移问题(根因):step01_check.py 的 parse_time_cn() / parse_time() 将 SMPTE 时间码的逗号从"小数点"改为"帧编号"语义(如 00:12,19 = 12+19/fps 秒,而非 12.19s);parse_template() 新增 fps 参数传递。step02_cut.py 的 -ss 移至 -i 之前(单次关键帧定位),配合正确时间戳后切分准确可靠。 |
| 3.1 | 2026-05-13 | 新增 copy_template.py 模板分发程序;step03_tts.py 新增数学符号口语化预处理(-→负/减、+→加、×→乘、÷→除以);step02_cut.py 修复切分偏移(保证最小1帧输出) |
| 3.0 | 2026-05-09 | 固定程序模式。完整的 AI 对话交互流程。讯飞超拟人主力 + edge备用。 |